
前回 これ何て読むの?よく使うIT記号まとめに続き、データベース(DB)の学習や実務で頻繁に使われる用語を、「読み方」と「意味」と一緒にまとめました。辞書代わりにご活用ください。
この記事でわかること
- データベースの基本構造
- データの整合性を守るルール
- 実務で使うSQL構文
- 現場で必須の重要用語
- 各用語の正しい読み方と実務での活用シーン
基本用語
データベースの構造を理解するための基礎的な用語です。
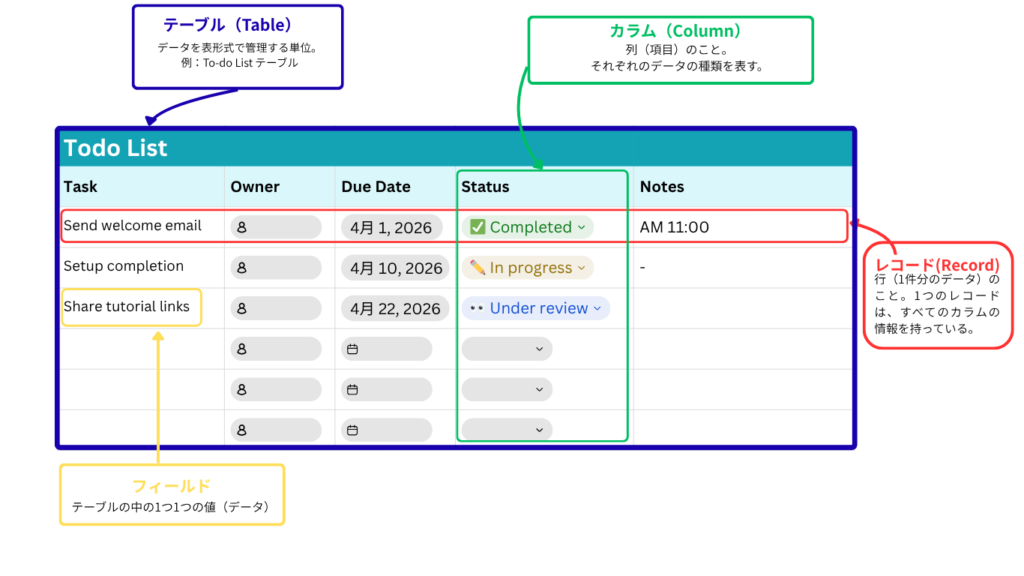
| 用語 | 読み(英語) | 意味 |
| データベース | Database | データを保存・管理する仕組み。 |
| テーブル | Table | データを表形式で管理する単位。 |
| カラム | Column / 列 | 縦の項目。データの内容を定義します。 |
| レコード | Record / 行 | 横のデータ。1件分のデータを指します。 |
| スキーマ | Schema | データの構造や設計図のこと。 |
キー・制約(Constraints)
データの整合性を保つための重要なルールです。
- 主キー(しゅキー / Primary Key): レコードを一意に識別するための特別なキー(PK)。
- 外部キー(がいぶキー / Foreign Key): 他のテーブルと関連付けるためのキー(FK)。
- NOT NULL(ノットヌル): 空(NULL)の状態を許可しない制約。
- UNIQUE(ユニーク): 値の重複を許さない制約。
- CHECK(チェック): 指定した条件を満たす値のみ許可する制約。
- デフォルト(Default): 値が入力されない場合に自動で設定される初期値。
- AUTO_INCREMENT: データを追加する際、自動で連番を振る機能。
データ操作・設計
設計段階やパフォーマンス改善でよく使われる用語です。
- NULL(ヌル): データが何も入っていない、空の状態。
- インデックス(Index): 検索を高速化するための「索引」。
- 正規化(せいきか): データの重複をなくし、効率的に管理するための設計手法。
- 非正規化(ひせいきか): 処理速度を上げるため、あえて重複を持たせる設計。
- リレーション(Relation): テーブル同士のつながり(関係性)。
- エンティティ(Entity): データの管理対象(実体)。
SQL関連(構文・操作)
実際にクエリ(命令文)を書く際に使用する基本的な用語です。
| コマンド | 読み方 | 意味 |
SELECT | セレクト | データの取得。 |
INSERT | インサート | データの追加。 |
UPDATE | アップデート | データの更新。 |
DELETE | デリート | データの削除。 |
WHERE | ウェア / ホウェア | データの抽出条件を指定。 |
JOIN | ジョイン | 複数のテーブルを結合。 |
ORDER BY | オーダーバイ | データの並び替え。 |
GROUP BY | グループバイ | データを特定のグループにまとめる。 |
LIMIT | リミット | 取得する件数を制限する。 |
実務重要用語(トランザクション等)
システム運用や障害対応で必須となる専門用語です。
- CRUD(クラッド): Create, Read, Update, Deleteの略。データ操作の基本機能。
- トランザクション(Transaction): 一連の処理を一つの単位としてまとめたもの。
- COMMIT(コミット): 処理の結果を確定させ、データベースに反映すること。
- ROLLBACK(ロールバック): エラー時に、処理を前の状態に取り消すこと。
- ロック(Lock): 他のユーザーによる同時更新を防ぐためにデータを固定すること。
- デッドロック(Deadlock): 互いにロック解除を待ち続け、処理が止まってしまう状態。
その他・管理用語
- ビュー(View): 複雑なクエリを一つの「仮想的なテーブル」として扱う機能。
- ストアドプロシージャ: データベース側に保存された一連の処理手続き。
- トリガー(Trigger): データの更新などをきっかけに自動実行される処理。
- マイグレーション(Migration): データベースの構造を変更・管理すること。
- バックアップ / リストア: データの保存と、保存したデータからの復元。
終わりに
データベース用語を正しく理解することは、スムーズな開発やチーム内のコミュニケーションに繋がります。「見て分かる」だけでなく「口に出して説明できる」よう、少しずつ覚えていきましょう!
